


Eroom's Law in the Age of AI
Quantity vs. quality in discovery research

The paradox
Last month a thread on X stood out to me:

The original statement captures a popular hypothesis about how to improve drug discovery, particularly in the AI era: accelerate an iterative process of design, synthesis, and experimental validation. The logic is straightforward: leverage computation to rapidly design small molecules, antibodies, or gene therapy vectors, synthesize these candidates, and experimentally evaluate their performance. Integrate these results into subsequent iterations of the cycle, automating and optimizing it for continuous operation. By compressing cycle time, this paradigm seeks to transform discovery research into an efficient search algorithm, enabling exploration of a larger space of potential candidates.
At the heart of this approach is the premise that drug discovery is bottlenecked by the speed of searching through potential solutions. The underlying intuition is that scaling experimental systems and enhancing search efficiency will accelerate the pace of discovery.
In fact, the past 50 years have brought remarkable advancements in the efficiency of discovery research: massively parallel assays, omics technologies, high-throughput screening, not to mention an increase in the raw volume of scientific reporting. Yet, paradoxically, the rate of drug approvals has declined—a phenomenon known as Eroom’s Law (Moore’s Law in reverse) (Fig. 1). Despite these technological strides, which can be interpreted as improvements in search efficiency, pharmaceutical R&D productivity has steadily worsened. This paradox challenges the assumption that speed and scalability alone are sufficient to solve the slowdown in new therapeutic discovery.
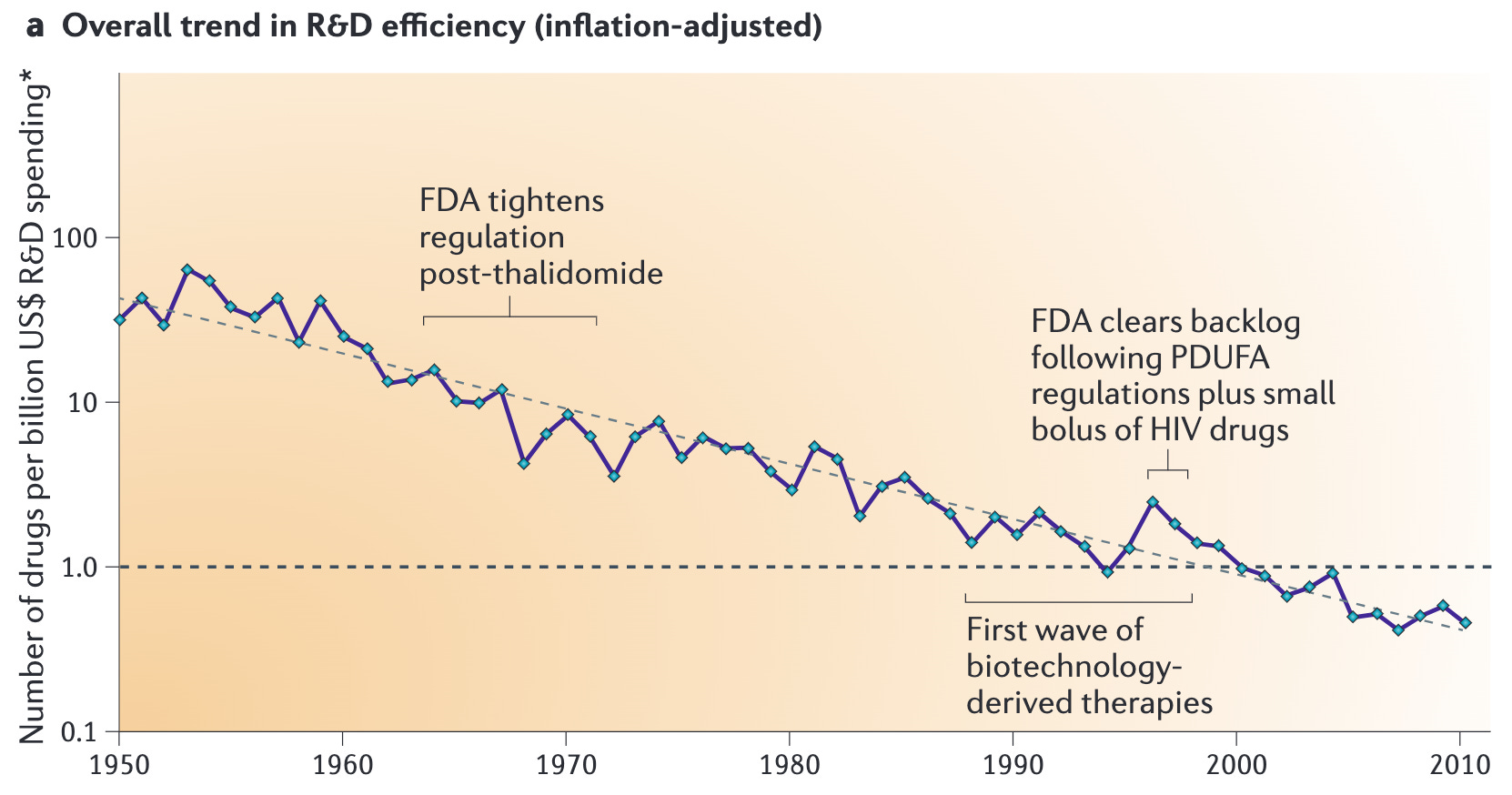
Quantity vs. quality
What explains this phenomenon, and how can we address it? There are likely many contributing factors1. A popular explanation is the low-hanging fruit hypothesis. This seeks to explain Eroom's Law by suggesting that the easiest and most accessible biological targets have already been successfully addressed, leaving behind increasingly complex and less tractable problems.
This perspective suggests that the solution space for these “harder” problems is significantly sparser. If our ability to search this space has truly improved, why aren’t we finding more solutions? One possible explanation is that the sparsity of the solution space (as we tackle increasingly challenging problems, akin to reaching for more elusive "fruit") is growing at a much faster rate than the capabilities of our search algorithms (the scalable scientific investigation of biology). However, testing this hypothesis is inherently difficult.
Other explanations have also been proposed. Notably, Scannell offers an insightful perspective on the trade-off between quality and quantity in research practices, highlighting the importance of predictive validity and reproducibility in driving meaningful progress. Originally detailed in When Quality Beats Quantity: Decision Theory, Drug Discovery, and the Reproducibility Crisis2 and further explicated in Predictive validity in drug discovery: what it is, why it matters and how to improve it3, Scannell argues that the issue may lie in the declining predictive validity of experimental systems. In response to the "design, build, test" proposal, Scannell’s X reply succinctly encapsulates the argument:
A narrow drug R&D thread following @sethbannon's broader biology post.... Fast "design, build, test" cycles ARE great in drug R&D when way therapeutic candidates score in the test is highly correlated with their clinical utility. But often it isn't. 1/8
"Design, build, test" cycles were often fast during the Golden Age of drug discovery (circa 1940 to 1970), partly because the lax regulatory environment meant new compounds were soon tested in people. Such test tended to be valid since people are good models of other people. 2/8
For a historical example, look how the sulphonamide antibacterials led to sulfonylureas (diabetes), thiazides (diuretics), and acetazolamide (an anticonvulsant). 3/8
History and decision theory suggest that today's biopharma industry is short of preclinical tests (aka "assays" or "models") that accurately predict the clinical utility of drug candidates in the diseases that are still commercially interesting. 4/8
The great untreated diseases remain the great untreated diseases either because they are intrinsically undruggable or because the model systems in which we test drug candidates typically give us the wrong answer (e.g., solid cancers, Alzheimer's). 5/8
Furthermore, the productivity loss from small decrements in test validity (e.g., by adapting the test to reduce cycle time or to increase throughput) can swamp large gains in brute-force efficiency. Quality beats quantity. 6/8
So, if I could hire genius clairvoyants for drug R&D, their 1st job would be picking tractable pathologies. Their 2nd second job would be maximising the predictive validity of disease models / assays. Only then would I unleash them on cycle times. 7/8
Should this line of argument apply to other areas of biology? I have no idea. 8/8
Scannell argues that declining predictive validity (PV)—the correlation between preclinical test results and clinical outcomes—is a major contributor to the observed decline in R&D productivity. Predictive validity refers to how well a decision tool's results align with a drug candidate's actual clinical utility. These “decision tools” encompass a broad range of methodologies, from lab assays and animal models to AI algorithms and expert human judgment. In my editorialization, this argument implies that modern research practices have favored scientific directions that esteem “brute-force efficiency” at the expense of methods that faithfully represent human biology.
Does this hypothesis explain the “Golden Era” of drug discovery? Scannell argues that in this era, researchers relied more on direct phenotypic screening in humans (very high PV!)—despite being low-throughput, lacking mechanistic insight, and often unsafe. The authors further propose that the decline in productivity can be attributed to the exhaustion of highly predictive models—a natural consequence of successfully developing treatments for diseases with well-defined targets. This hypothesis offers a more reasoned explanation than the “low-hanging fruit” argument. Rather than simply suggesting that the easiest targets have been depleted, it posits a root cause of poor experimental models.
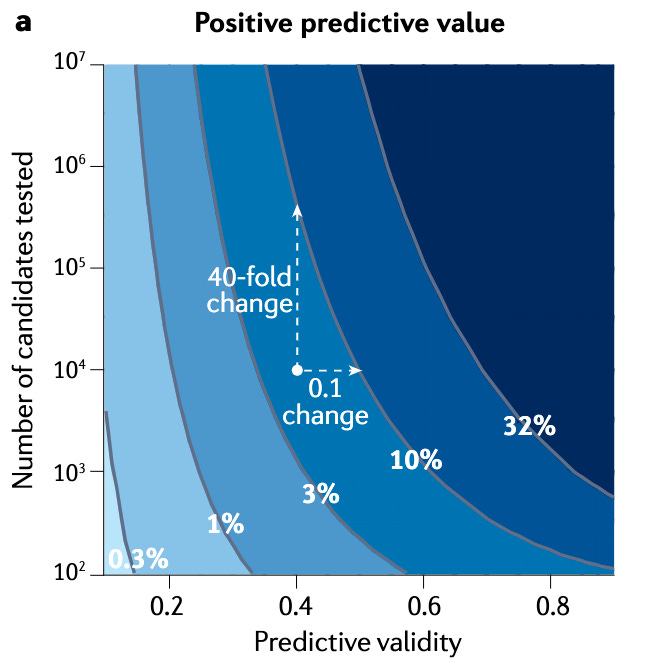
Scannell and Bosley's decision-theoretical model demonstrates that even minor improvements in predictive validity can significantly enhance the likelihood of identifying successful drug candidates. They show that a small, seemingly insignificant increase of 0.1 in PV (the correlation between a decision tool's output and clinical outcomes) can have a more substantial positive impact than increasing the number of candidates screened by a factor of ten (Fig. 2). They make an interesting point about potential biases in human interpretation of such results: such correlation improvements (0.1) are often perceived as minor and lost in experimental noise, whereas 10x increases in throughput or cost reductions are typically seen as significant.
Maybe it is worth reevaluating the assumptions we have baked into modern research practices. Maybe the shiny tools of science are blinding us from more parsimonious explanations. Focusing on quality, not just quantity, may be crucial to bringing therapies to patients faster.
In the Age of AI
So, if this hypothesis has merit, what are the implications in the Age of AI? It may not be enough to believe that speeding up search is enough. If we want to incorporate the “quality” hypothesis into our worldview, how does this recast our interpretation of popular scientific directions?
Take, for example, the emerging grand challenge of virtual cell modeling. The ultimate goal—simulating a single human cell, then a collection of cells, and eventually an entire organism—would ideally yield perfect predictive validity. But do we have the right data to achieve this vision? Can we reasonably expect that data harvested from highly scalable yet low-PV experimental systems will produce computational models with high PV? Perhaps not. However, it may be sufficient for some emergent properties to arise from these models, resulting in modest gains in PV. Combined with the massive scalability of in silico experimentation, this could move us towards higher rates of positive predictive value.

This perspective also informs a call to action for the bio-ML community: we should prioritize the predictive validity of modeling benchmarks. Designing relevant and robust benchmarks is arguably the core intellectual challenge of applied AI in biology. The scarcity of high-quality data often constrains us. If generating new and better benchmarks is not feasible, we must at least cultivate an acute awareness of where existing benchmarks fall on the spectrum of PV. At minimum, this awareness may help calibrate expectations for model performance. I think there may be promising research directions in exploring how the PV of training datasets informs model prediction confidence.
What other pathways come to mind that emphasize the predictive validity hypothesis in drug development programs? One compelling approach is to obtain clinical feedback earlier and faster. While I am not deeply familiar with the stringency and requirements for initiating a Phase I clinical trial—regulations that exist for good reason—there are examples of alternative pathways that accelerate clinical insights.
Consider, for instance, expedited pathways for rare or life-threatening diseases. Programs like the FDA’s Accelerated Approval or Breakthrough Therapy Designation aim to facilitate faster access to potentially lifesaving therapies. In rare diseases, where traditional trials are often unfeasible, N-of-1 clinical trials provide an alternative. Although such trials are frequently dismissed due to their small sample sizes, a single high-PV data point could, in many cases, be more valuable than 1000s of low-PV experiments. This perspective requires careful balancing: safety and rigor remain paramount. Yet, if PV is central to our strategy, these alternative pathways merit deeper exploration.
One recent research thread that comes to mind is recent work from Arcadia Science. Pulling directly from the abstract of Leveraging evolution to identify novel organismal models of human biology:
Biomedical research heavily relies on a few "supermodel organisms." Research using these organisms often fails to translate to human biology, limiting progress and clinical success. Recognizing these limitations, there's growing interest in expanding the diversity of research organisms. However, there's, as of yet, no optimal way to pair organisms with biological problems. Depending on the research question, each organism possesses distinct features that can be assets or liabilities. We developed a method to identify organisms best suited to specific problems and applied it to an “organismal portfolio” representing the breadth of eukaryotic diversity. We found that many aspects of human biology could be studied in unexpected species, broadening the potential for new biomedical insights.
The authors introduce a systematic approach to identifying novel research organisms for studying human biology. They analyzed the protein-coding genes of 63 diverse eukaryotic species and compared them to human genes using a newly developed molecular conservation measure. This measure incorporates both protein properties and structure (rather than sequence alone), while controlling for evolutionary relatedness to mitigate the influence of shared ancestry.
By identifying proteins in distant species that are functionally similar to human proteins, their method seeks to enable the strategic selection of organisms best suited to study specific biological questions. Exploring this research axis could be particularly impactful in the context of improving predictive validity for complex diseases.

Conclusions
The bespoke nature of drug development presents vast opportunities to industrialize biological research. I firmly believe that tighter design-build-test cycles will help transition biology toward an “engineering” discipline. In my blog post, Picks & Shovels of the AI bioeconomy, I even explore this framework as a business opportunity, describing it as “circular services” for the bioeconomy. I cast this more as an approach for streamlining services than a universal solution for vertically integrated drug discovery.
The Age of AI holds great promise for improving the efficiency of therapeutic discovery, as we are already witnessing. Yet, it is not a panacea. This is particularly true when we consider alternative hypotheses, such as the decline in predictive validity, as significant contributors to the stagnation of R&D productivity. Reductionist experimental systems, despite yielding large datasets, may fail to capture clinically relevant signals. Acknowledging this, it is crucial to integrate the concept of predictive validity into the design and evaluation of machine learning benchmarks.
We should continue exploring alternative pathways that emphasize predictive validity, such as Arcadia’s work on novel organismal models for human biology and efforts to accelerate clinical feedback. I hope this piece highlights an alternative interpretation to the challenges in drug discovery in the spirit of maintaining diverse scientific thought.
Scannell, J. W., Blanckley, A., Boldon, H. & Warrington, B. Diagnosing the decline in pharmaceutical R&D efficiency. Nat. Rev. Drug Discov. 11, 191–200 (2012).
Scannell, J. W. & Bosley, J. When quality beats quantity: Decision theory, drug discovery, and the reproducibility crisis. PLoS One 11, e0147215 (2016).
Scannell, J. W. et al. Predictive validity in drug discovery: what it is, why it matters and how to improve it. Nat. Rev. Drug Discov. 21, 915–931 (2022).