
Variational synthesis: a new generative design paradigm for biology
Bridging the gap between digital design and physical manufacturing

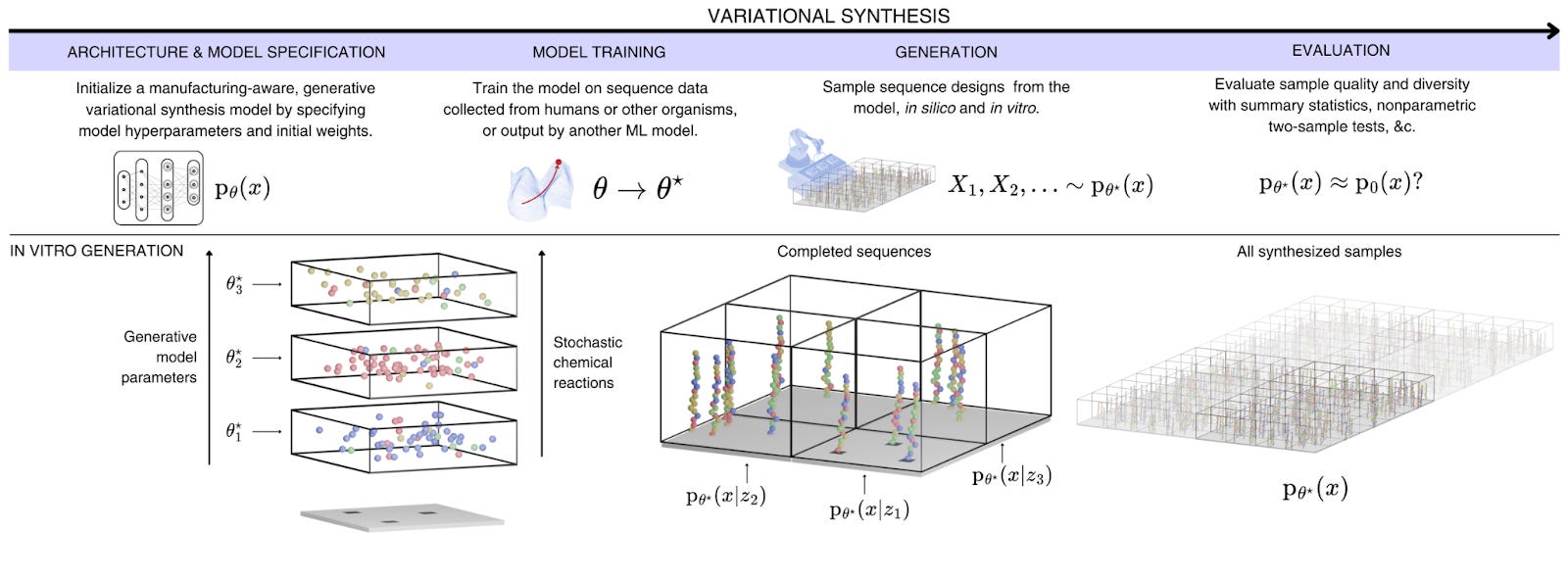
Variational synthesis is a novel approach presented by JURA Bio that bridges the gap between the physical and digital worlds. By probabilistically modeling the joint distribution of synthesis reaction parameters and sequences, it accounts for the possibilities of a target sequence distribution while adhering to the constraints of the manufacturing process. This enables the design of sequences that can be both digitally specified and physically produced at massive scale.
If you, like me, think that physical validation is the real bottleneck in generative design approaches in biology, this should make you very excited. At a deeper level, variational synthesis also suggests what is possible if deterministic manufacturing processes are reframed through a stochastic lens.
My goal is to provide intuition behind this approach while highlighting some of the core results from the original theoretical work and the more recent applied research.
Challenges in current biological sequence design
While recent advances in computational methods have enabled the design of DNA and protein sequences, these digital designs must still be physically synthesized and tested in the lab—a critical bottleneck in the pipeline. Despite our ability to generate thousands of candidate sequences in silico, only a small subset can be synthesized and tested due to practical constraints.
In current workflows, only a limited number of computationally designed sequences are selected for synthesis because each sequence needs to be individually constructed—typically capping the number at around 105 (which is actually a substantial library). Let’s think of this as a "targeted search" approach.
Another strategy is to build “degenerate” libraries, where every possible permutation of a sequence is synthesized. However, this "uniform search" approach quickly becomes impractical as sequence length increases, also resulting in an overwhelming number of random, non-functional sequences.
After synthesis, these sequences undergo functional testing. As you can see, both approaches have significant limitations in terms of scalability and efficiency.
Understanding variational synthesis
The term variational synthesis is inspired by variational inference, a probabilistic method for approximating complex distributions. By learning the optimal ratios of available sequence templates needed to recreate a target sequence distribution, variational synthesis essentially learns the "recipe" to manufacture large libraries of biological sequences in a single pooled experiment.
The wet-lab validation of this paradigm comes from JURA Bio’s recent paper, Manufacturing-Aware Generative Model Architectures Enable Biological Sequence Design and Synthesis at Petascale. The abstract highlights the impact:
We make our generative models manufacturing-aware, such that model-designed sequences can be efficiently synthesized in the real world with extreme parallelism... Using previous methods, synthesis of a library of the same accuracy and size would cost roughly a quadrillion (1015) dollars.
There's an accompanying blog post, and the theoretical work underpinning this approach was actually published a few years ago, along with the code.
This concept took me a moment to truly digest. Let me reiterate the core idea: the model is specified with parameters that map directly to the actual DNA synthesis process. These parameters are then optimized to maximize the likelihood of producing a desired sequence distribution (i.e., the training data). The paper demonstrates this with examples including antibodies, T cell antigens, and DNA polymerases. The models even match state-of-the-art protein language models in approximating the training distribution.

But what sets this apart? Haven’t we already built powerful generative protein and DNA language models? The key innovation lies in the learned synthesis parameters—these parameters serve as a precise recipe to construct a pooled library of sequences in the lab that reproduces the target distribution.
But how do you translate learned parameters into physical manufacturing? This is the most profound insight: pooled synthesis is, by nature, a stochastic manufacturing process, making it an ideal match for the framework of probabilistic modeling.
A simple example
First, a primer on pooled synthesis. In simple terms, pooled synthesis involves building a huge library of sequences step-by-step by adding nucleotides in controlled ratios. This approach allows the simultaneous creation of thousands to millions of unique sequences in a single experiment.

Let's illustrate with a simple example. Suppose we want to construct a library of 10,000 oligonucleotides (oligos) with a sequence length of 5 to study how different upstream sequences influence the expression of gene X. We know that, for stability reasons, the sequence must start with an A, and the third position must be either an A or a G. To create a diverse library for functional screening, we will add nucleotides in specific ratios and chemically bond them at each position, progressively building the oligos one nucleotide at a time:

Using this recipe, we will synthesize a population of oligos that reflects the distribution of nucleotides at each position. In variational synthesis, instead of pre-specifying these ratios, we learn the distribution parameters for each sequence position.
But how do we learn these parameters? In this example, we used prior knowledge to define the constraints: the sequence must start with A, and the third position must be A or G. This prior knowledge comes from approximate rules derived from the literature. But I bet there are exceptions to these rules. Let's say we examine all 5-nucleotide sequences upstream of gene X in online databases and find that A appears in the first position 97.6% of the time. Yes, usually the sequence starts with A, but evolution hasn't completely eliminated other nucleotides from this position. Maybe other downstream nucleotide combinations compensate for stability.
Instead of relying on these rigid rules, we use probabilistic inference to approximate the evolutionarily conserved sequence distribution. Since the dataset is large, complex, and high-dimensional, we learn these parameters iteratively, using an expectation-maximization (EM) algorithm. In the end, the learned parameters more accurately reflect the natural diversity of sequences:

When we build the sequence library using these ratios, we obtain a population of oligos that much more closely reflects the evolutionary data. Naturally, the synthesized library will still maintain an element of stochasticity.
The discussion section of the paper summarizes the idea succinctly:
Variational synthesis models achieve petascale synthesis via a manufacturing-aware model architecture, which accounts for the possibilities and constraints of stochastic DNA synthesis technology. Variational synthesis models are therefore both enabled and limited by available experimental tools for DNA synthesis.
Further results
The research extends far beyond this simple example, incorporating more practically applied manufacturing techniques such as combinatorial assembly, mutagenesis-based library construction, and optimized codon vocabularies.
The paper also introduces an intriguing approach: leveraging auxiliary models like protein language models (PLMs). Since PLMs already capture an estimate of global sequence fitness, the authors conditionally generate 250k DNA polymerase sequences via ProGen2 and use this as training data for variational synthesis. This is similar to knowledge distillation, and more broadly, falls under the category of transfer learning. They do caution, however, that using one model's output as another's input carries inherent risks.
The bigger picture
Finally, the authors make a salient forward-looking point. With the access that variational synthesis provides to vast libraries of likely functional proteins/sequences, new high-throughput methods are needed to functionally characterize activity at much higher resolution. In current libraries, where most sequences are non-functional, coarse readouts are sufficient to identify the few true positives. However, with many viable candidates, more sophisticated functional characterization will be required to understand nuanced trade-offs.
I found this work incredibly impactful—not only because it addresses a major validation bottleneck for generative methods in fields like protein design, but also because the framework could have broad applications in the physical sciences. Obvious extensions include small molecule libraries in chemistry and materials science. While I'm not familiar with reaction synthesis, it seems plausible that using variational synthesis with techniques like click chemistry could help enrich for more functional compounds.
On a more abstract level, rather than simply applying variational synthesis to existing stochastic manufacturing methods, we can reimagine traditional, deterministic manufacturing processes as stochastic systems. Maybe this is the "assembly line" of the generative AI era: scalable manufacturing of diverse, unique items.
Variational synthesis offers a transformative approach to bridging the gap between digital design and physical manufacturing. By integrating the manufacturing constraints of stochastic synthesis directly into the generative model, it enables the creation of extensive libraries that are both feasible to synthesize and representative of desired distributions, such as evolutionary landscapes.
Thank you to Eli Weinstein of JURA Bio for technical review.